网络处理器芯片主要用于构建网络通信基础设施平台,对于位于网络通信终端节点的用户来说,通常是透明而不可见的。因此,与通用CPU以及嵌入式CPU等大众电子消费密切相关的通用处理器芯片相比,网络处理器(Network Processor)芯片一直以来很少能够获得广泛的关注。
实际上,网络处理器广泛应用于包括路由器、交换机等各类网络核心设备中,它特定应用于网络通信领域的各种任务,例如报文处理、协议分析、路由查找、防火墙以及QoS等。网络处理器芯片对于网络通信基础设施的重要性,阿尔卡特朗讯公司的 Basil Alwan有一句话形容得很贴切,“网络处理器是网络设备最根本的基因,它定义了路由器平台的能力、可扩展性以及面向未来演化的可能性[1]”。
国内外研制情况
经过多年的发展,网络处理器正逐渐替代网络通信设备中固定功能的ASIC芯片,已成为构建网络通信系统的战略性核心器件。商用网络处理器市场在不断增长,而市场上网络处理器芯片产品则基本上来自国外厂商。
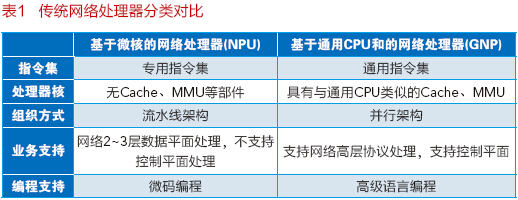
传统网络处理器按核心处理单元的不同可以分为两类,即基于微核的网络处理器(NPU)以及基于通用CPU核的网络处理器(GNP),主要区别如表1所示。
目前,典型商用网络处理器芯片包括阿尔卡特朗讯的FP系列[1]、Marvell 公司的Xelerated系列[2]、EZchip的NP系列[3]等。上述网络处理器通常采用多核多线程、超流水等高级体系结构,利用功能部件定制优化、深亚微米集成电路设计等技术提高报文处理性能,其中多款网络处理器可以达到400Gbps报文处理要求。
阿尔卡特朗讯公司的FP3网络处理器集成共288个RISC Core,主频可达1GHz,其中每32个Core为一个Cluster,共9个Cluster。它采用多Pipeline处理模型,FP3的报文转发处理能力高达400Gbps。与FP3类似,Marvell公司的HX4100网络处理器(原Xelerated公司)也采用类似的多Pipeline处理模型,通过集成数百个支持VLIW指令集的PISC(Packet Instruction set computer)专用处理器核,也可实现400Gbps线速报文处理。值得一提的是,HX4100流水线间得PISC采用同步数据流体系结构,从而避免了控制流模型中的指令相关性对性能的影响,可确保系统获得确定性的处理性能。EZchip的NP-5采用Functional Pipeline处理模型,处理流程映射到4级面向任务优化的处理引擎,采用专用指令集,基于功能编程语言(FPL)开发,分组处理能力达到240Gbps。上述芯片产品都属于基于微核的网络处理器,大多采用流水线方式组织,以提供极高的报文转发处理性能,在芯片功耗方面具有优势,主要缺点是通常仅支持微码编程,软件开发复杂困难。
Broadcom公司的XLP II 900网络处理器[4]集成了多达80个通用CPU核(nxCPUs),具有三级Cache存储子系统和4个DDR3内存控制器,采用并行处理架构,可提供160Gbps报文转发处理性能。通过集成安全加速引擎,其可支持高性能的加密、认证以及深度报文检测等功能。Cavium公司的OCTEON III网络处理器[5]也采用并行架构,通过集成48个64位MIPSCPU核和大量的加速引擎,可提供100Gbps报文转发处理能力,并支持广泛的网络业务处理硬件加速。上述芯片产品都属于基于通用CPU核的网络处理器(GNP),面向支持多样化网络高层协议和业务处理设计,具有较强的可编程性,通常可以支持C/C++高级语言编程,并运行通用Linux操作系统,从而为开发人员带来便捷。然而,集成度与功耗问题严重制约了GNP的性能提升。
从国内来看,华为、中兴等网络设备厂商以及国防科大等科研院所早已基于国外成熟网络处理器芯片设计了多款高性能路由器产品,并已经在国内外市场上得到广泛应用。国防科大、西安电子科大以及清华大学等单位在国内也较早开展了网络处理器研制,取得了一定进展和技术积累,但与国外仍有一定差距,目前还没有成熟的国产商用网络处理器芯片产品。
随着国家战略层面对网络通信基础设施安全及自主创新能力的重视,作为构建网络通信设备的核心器件,网络处理器芯片的国产化将是一种必然。为了选择一条切实可行的网络处理器研制的技术途径,必须充分把握网络处理器研制所面临的挑战和技术发展趋势。
研制挑战与技术趋势
与通用CPU不同,网络处理器芯片研制一方面涉及网络通信、微电子、操作系统以及处理器体系结构等多个领域的技术,设计难度大;另一方面其处理性能必须能够匹配飞速增长的网络接口带宽需求,硬性要求高。因此,网络处理器芯片复杂度高、实现困难,其研制周期长,投入资金高昂,研发难度非常大,这也是国产商用高性能网络处理器迟迟未取得突破的重要原因。以思科公司为例,其SPP网络处理器于1999年开始设计,2003年才在cisco的第一台集群路由器CRS-1中使用;而其在2008年设计完成的QFP网络处理器前后共花费1亿美金才研制成功,商用高性能网络处理器的研制难度可见一斑。
从技术发展趋势看,随着软件定义网络(Software Defined Network,SDN)、网络功能虚拟化(Network Function Virtualization)等技术的出现和发展,对网络通信设备的可编程性提出更高要求。不断演化的网络通信业务和协议也要求构建网络通信设备的核心器件必须能够易于编程开发,以期加快系统研制进度、降低开发成本并实现投资保护。基于通用CPU核的网络处理器GNP虽然提供高度的可编程性支持,然而在功耗及芯片集成度方面的天然劣势使其难以满足飞速增长的网络通信带宽的需求。
针对上述问题,Intel公司提出未来的通信处理平台应该以通用多核CPU为核心,采用芯片组方式,从而在性能与可编程性间获得完美折衷。Intel的Crystal Forest通信处理平台[6]采用双Xeon处理器作为分组处理的主要功能单元,通过集成片外QuickAssist加速器,将DPI、加解密以及解压缩等常用的分组处理功能卸载到QuickAssist加速器中。从软件层面看,QuickAssist通过提供加速器抽象层,隔离各种物理实体,从而允许上层软件都通过统一接口访问多样化的硬件加速器。虽然,Crystal Forest通信平台目前仅可以支持约100Gbps的流量的线速处理,与业界高性能网络处理器有一定差距,但是我们认为Intel提出的基于通用多核CPU的多芯片解决方案值得思考和借鉴。多芯片解决方案可以有效缓解对网络处理器芯片设计的性能压力,并在系统升级、部署方面提供更大的灵活性。在思科以及阿尔卡特朗讯最近推出的高性能核心路由器中(例如思科CRS-3),高性能转发线卡都集成多个处理芯片协同完成分组转发处理业务。
国产化技术途径
在把握了网络处理器芯片研制挑战以及发展趋势的基础上,我们认为基于国产通用多核CPU+可编程网络处理引擎(NPE)的架构是网络处理器芯片国产化一条现实可行的技术途径。实际上,网络处理器研制与高性能CPU及通用操作系统研制有很多共性技术,例如高性能RISC核设计、片上网络、低延时高带宽的存储器接口、操作系统和编译系统等。以飞腾、龙芯为代表的国产通用多核CPU以及以麒麟为代表的国产操作系统在国家核高基等项目支持下已取得巨大突破,其相关成果已经在国家信息系统建设中发挥重要作用。因此,有效利用国产高性能CPU和操作系统的研究成果,并对其网络处理能力进行充分挖潜,是缩短国产网络处理器芯片研制周期,降低研制成本和风险的有效途径。
然而,通用多核CPU主要面向通用计算领域设计,适用于计算密集型的应用。而网络处理器则主要面向网络处理领域设计,适用于访存密集型应用。如何提高通用CPU的访存计算比(MCR)是决定能否利用通用CPU进行网络处理的关键。针对这一问题,国防科技大学课题组对网络处理器实现模型和途径进行了深入研究和探索,提出应摆脱传统以多核软件为核心的实现模型,由可编程硬件(即NPE)定义网络报文的处理路径,并对性能敏感的功能进行硬化卸载,从而有效降低通用多核CPU软件的处理压力,实现系统性能提升。这种“硬件定义”的处理模型允许在不改变现有通用多核CPU内部架构、不对其内部实现进行特定优化的前提下,缩短网络处理器研制周期,降低研制成本,从而有效加速网络处理器芯片的国产化进程。
总结
网络处理器芯片作为构建网络通信基础设施的核心器件,其国产化必须综合考虑芯片的设计复杂度和研制难度,准确把握技术发展趋势。我们认为,国产通用多核CPU与可编程网络处理引擎(NPE)相结合的体系结构是解决网络处理器“中国芯”的问题的一条希望之路。
参考文献:
[1] 阿尔卡特朗讯FP3网络处理器[R/OL],http://www.alcatel-lucent.com/products/fp3.
[2]Marvell Xelerated网络处理器[R/OL],http://www.marvell.com/network-processors/xelerated-hx/.
[3]EZchip NP-5网络处理器[R/OL],http://www.ezchip.com/p_np5.htm.
[4]Broadcom XLP900网络处理器[R/OL], http://www.broadcom.com/products/Processors/Enterprise/XLP900-Series
[5]CaviumOcteon III网络处理器[R/OL],http://www.cavium.com/OCTEON-III_CN7XXX.html.
[6]TianTian, Alexander Belousov. Intel下一代通信平台数据平面解决方案