1 引言
Internet上信息资源的飞速增长,使得人们越来越习惯于在网络上搜集自己所需的信息。其中各类文献资源信息也以电子文档的形式,在网络上广为传播。然而要从庞大的文献资料库中准确、方便、迅速地找到并获得自己所需的信息,却往往比较困难。传统的基于关键词匹配的文献信息检索方式存在一些弊端,如“忠实表达”、“表达差异”[1]等问题。这种方式对文献资源的处理粒度大,网络搜索引擎在执行用户查询的时候,只是提取用户查询请求中的关键词,会丢失用户查询的语义信息和相关同义、近义以及上下位关系外延的资料信息,这些直接导致检索结果的不准确。以关键词检索文献资源的方式无法提供高质量的知识服务。
解决上述问题的关键在于把资源检索从传统的关键词层面提高到语义知识层面。Tim Berners-Lee于2000年提出了语义Web[2]的概念。语义Web是一种能理解人类语言的智能网络,它的实现能有效提高互联网使用效率。要实现检索系统的语义化,很自然的需要引入本体(Ontology)[3]。Ontology作为语义Web的核心概念和技术,本身具有一定的推理能力和概念知识结构,能很好的描述实例的内涵及实例与实例之间的关系,经过推理还能表示隐含的各种知识之间的关系。通过本体,搜索程序可以进行基于语义的精确搜索,可以把页面上的文献资源与某些知识结构和规则链接起来。基于Ontology 的文献领域语义检索机制可以从语义层上支持对文献资源的查询和共享,从而在一定程度上提高了文献检索的查准率和查全率。
2 文献本体的构建
2.1 本体知识
在语义Web中,Ontology具有非常重要的地位,弥补了资源描述的不足,是解决语义层次上Web资源共享和交换的基础。Studer等人认为"An ontology is a formal specification of a shared conceptualization"[4],这个是目前为止最完善的本体的定义。文献[5]分析了本体的概念、本体描述语言、本体的分类、本体的构建原则。文献[6]给出本体包含的4层含义、本体的目标、领域本体及其构建。总结这些文献资源可以发现:本体不仅提供了对领域知识的捕获、描述和共同理解,还给出不同层次模型中概念间相互关系的明确定义,具有较强的表达能力。本体的核心就是知识共享,通过减少概念和术语上的歧义,使得人们和组织(或者机器)之间的交流准确无歧义。
2.2 本体构建方法
一个本体由多个概念以及关系组成,本体的创建就是用来表达概念和概念之间的各种关系。根据具体工程和领域的不同,形成不同的构建方法。文献[7]详细介绍了本体的构建方法,如七步法、生命周期法、骨架法、IDEF-5方法等。文献[8]以七步法的思路为基础,综合生命周期法和软件工程的原型法,以骨架法为本体构建的指导方针,提出了一个创新的构建领域本体的原型七步法,过程是螺旋式上升的,符合人们的思维认知规律,操作性和扩展性强。
2.3 文献本体的构建
文献领域知识库的建立是实现语义检索和推理的关键步骤。本文以七步法的方法为基础,根据文献资源本体构建的需要,提出一种较为简单的本体构建方法,图1描述了该构建方法的流程。

图1 本体构建流程图
文献领域本体描述了文献中的实体、实体之间的各种关联以及实体的属性和关联的属性。基于本体的文献语义检索系统中关注文献(Paper)、作者(Author)和期刊(Magazine)三类重要的概念实体。三个概念又通过相应的属性关联起来,定义了三个对象属性(ObjectProperty),其中isPublished描述了文献与期刊之间的出版关系,其定义域是Paper类,值域是Magazine类;Citing(isCited)等属性的定义域和值域都是Paper类,它描述了论文与论文之间相互引用的关系;对象属性hasAuthor定义域为Author类,值域为Paper类,它描述了作者与文献之间的关系。建立的文献领域本体如图2所示。用户通过检索文献可以了解到文献的作者、内容、类型、关键词、发表时间、引用和被引用的文献等。而同引和同被引可以通过文献的引用和被引用情况推理出来。
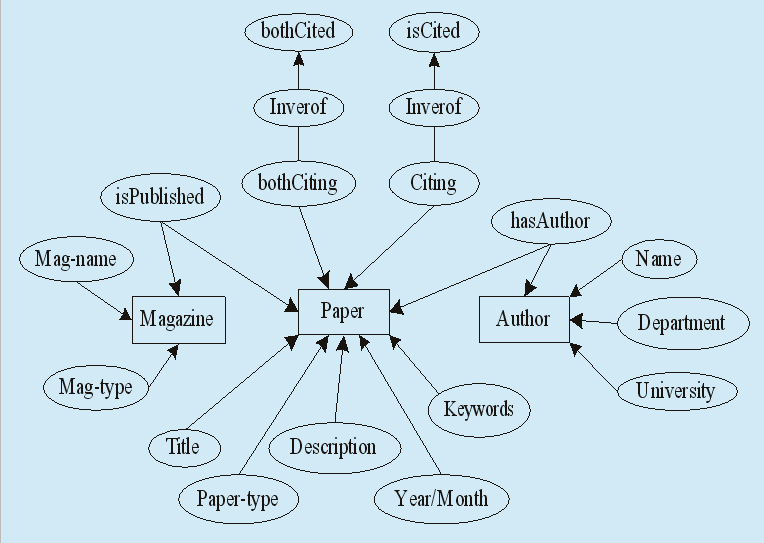
图2 文献领域本体
3 文献领域语义检索的实现
3.1 基于本体的文献领域语义检索模型
分析了传统的文献检索模型之后,提出了基于Ontology的文献领域语义检索系统模型,如图3所示。该模型采用基于B/S 的三层结构,即把该系统分为三层:表示层、业务逻辑层和数据层。用户向系统发出检索请求,系统对检索请求进行信息提取,根据检索信息和所定义的语义规则对文献领域本体进行语义推理,从而实现用户的检索要求。
3.2 实验环境及工具
本系统所使用的开发工具为Java、Jena2.5、protégé3.4本体开发工具;使用OWL本体描述语言和SWRL规则语言[9];Tomcat6.0作为Web服务器;实验环境为:CPU InterCore 2、1.83GHz、1G内存、80G硬盘的Windows XP操作系统进行实验。
3.3 系统语义推理
基于Ontology的文献领域语义检索系统,是关于语义层面的检索,关键在于概念及其概念之间关系的推理,这种推理可以将隐含在显式定义和声明中的知识通过一种处理机制提取出来,即根据用户提交的语义查询进行相应的语义扩展,譬如可以从检索出的文献引用关系中推理出它的同引和同被引文献。然而这种推理需要相应的规则,没有规则系统是无法理解本体概念之间的语义,只能进行关键字机械的匹配。Jena是基于规则的推理机,因此在基于本体的文献检索系统中建立了能真实表现概念之间关系的规则,实现系统的语义理解,从而检索出满足用户需求的信息。
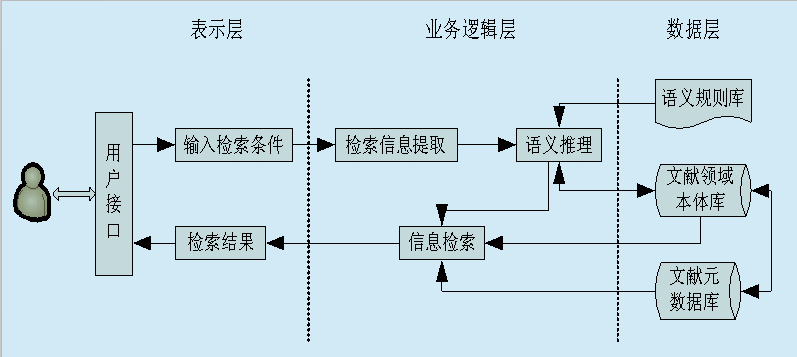
图3 基于Ontology的文献领域
语义检索系统模型
(用户自定义规则的补充表达),使得在protégé下编辑规则,更加灵活和直观。首先自定义了一组语法:符号“→”表示蕴涵,将前提和结论逻辑关联起来;变量以“?”开头;引用的子公式插入符号“∧”进行连接;同时提供内置函数,类似方法调用,返回值为变量的值。

以一阶谓词逻辑的角度来分析上述规则,可以得到如下的语义:如果变量x是类A的实例,同时也是类B的实例,那么变量x也是类C的实例。其部分推理规则如下所示:
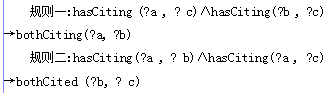
规则一说明:文献a引用了文献c,文献b也引用了文献c, a和b的关系为不相等,则可以推出a和b的关系为同引(bothCiting)关系;规则二说明:文献a引用了文献b,文献a又引用了文献c ,b和c的关系不相等,则可以推出b和c之间是同被引(bothCited)的关系。
4 实验结果与分析
通常用查准率(Precision)和查全率(Recall)来衡量智能信息检索系统的性能。查准率主要描述的是检索结果的有用性,是检索结果中有效信息量与检索总量之间的比例关系。查全率主要描述检索结果的遗漏情况,表示的是信息检索结果中有用信息量与用户需求信息量之间的比例。设检索出的文档数目为N, 检索出的相关文档数目为Ra, 所有相关文档数目为Rb,则查准率和查全率的计算方法如下:
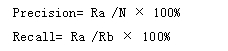
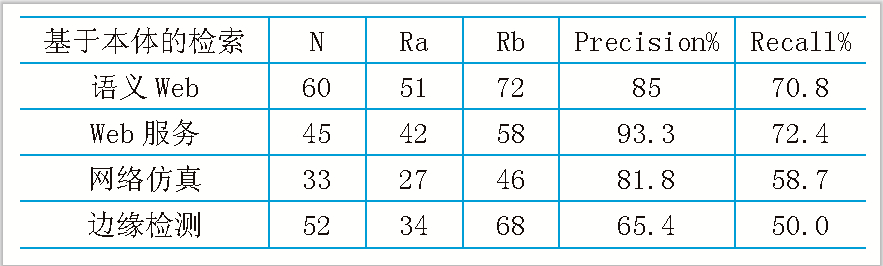
表1 基于本体的文献语义检索结果
本文选取互联网上计算机领域的相关科技文献作为实验对象,以2008-2011年期间的在计算机相关期刊上发表的学术论文,针对计算机不同的领域,选取300篇文献作为本体库。对采用Ontology技术前后的检索性能进行比较, 得到的结果如表1、2所示。
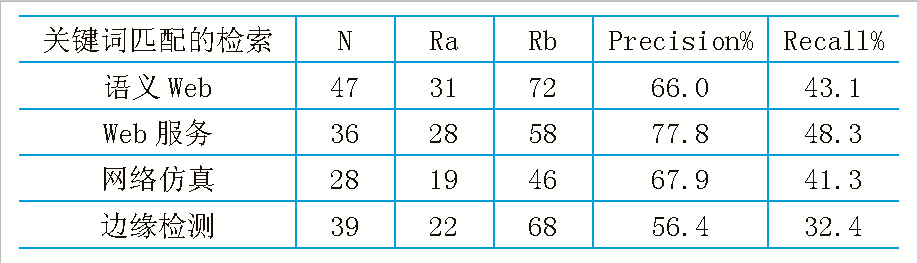
表2 基于传统关键词匹配的检索结果
实验结果表明:基于Ontology的文献检索系统返回符合检索条件的大量的、精确的文献资源,包括文献编号﹑标题﹑作者﹑关键词﹑文献出处﹑内容﹑同引和被同引等详细内容信息。本系统的查全率与查准率高于传统的关键词检索的效率,这主要是因为系统在本体的基础上对检索关键字进行了语义的分析、扩展和推理。因此将本体技术应用到文献检索领域是可行的。
5 结束语
结合文献信息的特点,本文提出了一个新的本体构建方法,创建了文献领域本体,建立了推理规则,构建了一个文献领域语义检索系统模型。该模型可以方便、快捷的查找出目标文献。用户向系统输入检索请求可以通过对本体的推理,检索出目标文献引用的文献、引用目标文献的文献、同引关系和被同引关系的文献。最后通过实验,验证了基于本体的文献领域检索系统的优越性。
参考文献:
[1] 朱庆生,邹景华.基于本体论的论文检索[J].计算机科学,2005.32(5):172-173,176.
[2] T BERNERS-LEE,J HENDLER,O Lassila[J].The Semantic Web.NewYork:Scientific American,2001:284(5):34-43.
[3] What is an ontology?[CP/OL].[2011-02-10].
http://www-ksl.stanford.edu/kst/what-is-an-ontology.html
[4] FENSEL D.ONTOLOGIES.Silver Bullet for Knowledge Management and ElectronicCommerce[M]. Stanford:Springer,2001:50-53.
[5] 刘垣,君忠.本体理论及其在E-Learning中的应用[J].计算机应用与软件,2012,29(4):114-117.
[6] 柴留祥,何丰.基于Jena及其本体推理的研究[J].计算机技术与发展,2011,21(11):117-119,123.
[7] USEHOLD M.Ontologies principles,methods and applications[J].Knowledge Engineering Review,1996,6(11):2-3.
[8] 梁婷婷,李春青.一种领域本体构建方法及其在相片管理中的应用[J].计算机系统应用, 2012.12(5):140-144,104.
[9] 陈布伟,李冠宇,张俊,李佳燕.基于语义网规则语言的推理机制框架设计[J].计算机工程与设计,2010,31(4):847-849,853.